搜索到
9
篇与
的结果
-
 【家庭系统观察笔记 01】当“救世主”遇到“理想家庭”:一场完美治愈的心理陷阱 本文故事素材源于对多个家庭心理咨询案例的综合与提炼,旨在探讨家庭系统动力学的普遍模式,而非记录任何特定家庭或个人的真实经历。为保护当事人隐私并严格遵守咨询伦理,文中所有人物、情节、对话及关键细节均经过深度虚构和艺术加工,与任何现实中的个人或家庭均无对应关系。请读者切勿对号入座。本文的重点在于知识分享与人性反思,而非纪实报道。前段时间,我的朋友小A,一位专攻家庭治疗的心理咨询师,接手了一个棘手的案子。委托人是一位母亲,她因为自己15岁的儿子突然表现出强烈的社交回避而焦虑万分——那个曾经活泼的孩子,如今把自己锁在房间里,只通过门缝递纸条与家人交流。心理咨询初期,一切都顺利的不可思议。母亲详尽地描述了家庭的困境。在她零散而充满情绪的讲述中,这个家庭的轮廓逐渐清晰起来:一位追求完美、沉默寡言的建筑师父亲;一个仿佛天生带着情绪雷达的儿子,他总能从父亲放钥匙的声响和母亲的一声叹息里,精准地判断出家里今天的“天气”,并下意识地让自己变成最不占空间、最安静的那件家具;以及她自己,一个在丈夫的沉默和儿子的封闭之间疲于奔命的焦虑核心。当她倾诉完后,小A没有提供任何解决方案,只是精准地复述了她混乱感受中的核心——孤独。那位母亲愣了许久,然后轻声说:“和您谈话,我第一次感觉自己不是一个需要被修理的病人。”那句“不是病人”仿佛是一把钥匙,彻底打开了她信任的闸门。 在接下来的几周里,她不仅将积压多年的烦恼与焦虑倾泻而出,更像一名最虔诚的学生,贪婪地阅读小A推荐的每一本书,笔记本上写满了密密麻麻的心得。她不止一次在咨询结束时,眼中闪着光对小A说:“我感觉自己被治愈了,整个家都好像被照亮了。”而对小A而言,这份全然的信任不只是专业的认可,更像是一剂注入疲惫灵魂的强心针。家庭心理咨询本就是个吃力不讨好的领域,来访者们往往身处痛苦的漩涡,自然会渴望立竿见影的改变;或是出于自我保护的本能,难以在短时间内卸下心防。对于小A这样共情能力极强、甚至到了会过度透支自己来维护关系的理想主义者来说,这种不被信任的消耗是巨大的。因此,这位母亲的出现,就如同在漫长而崎岖的跋涉中,突然遇到了一片水草丰美的绿洲。这片绿洲的意义,很快就远超一份工作。这个家庭的轮廓,像一枚尘封的旧邮票,精准地贴合在他记忆的某个角落。那追求完美的父亲,让他想起自己童年时那个永远无法被取悦的背影;那过度懂事的孩子,简直就是中学时代的他自己,永远在察言观色,生怕行差踏错。“这是命运的安排,”小A在一次与我深夜长谈时,眼中闪着异样的光彩,“有这位母亲的全然信任,我感觉自己像一个拿到时空钥匙的人,终于可以回到过去,对那个无助的小男孩说:‘别怕,我来拯救你了。’这会是一个完美的闭环。”一个完美的救赎故事,一个理想的治愈开端。然而,在心理咨询的地图上,过于平坦顺利的开局,往往指向最危险的悬崖。小A感受到的“自我疗愈”和母亲体验到的“被照亮”,真的是一剂良药吗?或者,这只是这个家庭系统为了自保,上演的一出更精妙的金蝉脱壳?要看穿这层迷雾,我们不能再盯着某一个人看,而需要戴上一副叫做家庭系统动力学(Family Systems Dynamics)的广角镜。戴上它,你会发现,家庭不是一堆积木,而更像一个悬挂在婴儿床上的、由各种小物件组成的风铃。父亲、母亲、儿子,就是风铃上三个相互牵制的挂件。在这个家里,父亲这枚最重的挂件,主动选择静止,他用沉默和疏离,拒绝参与任何摇摆。 但系统的能量不会消失,为了维持整个风铃不至于彻底死寂,母亲就必须过度补偿,她变成了那个最轻、最敏感的铃铛,用加倍的焦虑和不停的摇晃,来填补父亲留下的能量真空。而儿子呢?他悬挂在这“绝对静止”和“疯狂摇摆”之间。一边是冰冷的重压,一边是混乱的噪音。为了不被这两种极端的力量撕碎,他唯一的选择就是——让自己失灵。他把自己变成一个缠绕的、不会响的死结,用这种方式,同时抵抗父亲的静和母亲的动。你看,从来没有独立的问题。儿子的“封闭”,是这个失衡风铃系统下,必然产生的结果。这个系统最狡猾的地方在于它的惯性。它就像一个老旧的中央空调,几十年来,全家都习惯了它吹出的、令人窒息的30度“焦虑暖风”。虽然每个人都汗流浃背,但这毕竟是他们唯一熟悉的温度。突然有一天,儿子用社交回避这个行为,把温度计砸了,警报声大作。这其实是系统内部的一次求救。现在,小A来了。他以为自己是来修理空调的救星,但他没意识到,这个系统太强大了,它不想要被修理,只想快速消除警报。于是,系统巧妙地把他收编了。小A不是修理工,他成了一块被递到母亲手里的“冰毛巾”。 母亲把对丈夫的失望、对儿子的无助,全部转化成对这块“冰毛巾”的依赖和赞美,暂时感觉凉爽了。而小A,则因为这块毛巾精准地贴合了自己童年时渴望被认可的伤口,而感到了前所未有的满足。一个愿打,一个愿挨。母亲将对丈夫和儿子的失望与期待,全部转移到了这位“理想老师”身上;而小A,则将自己对童年缺失的补偿渴望,投射到了这个“理想家庭”上。但冰毛巾总会变热,空调的本质问题没有解决。当暂时的凉爽退去,那股熟悉的、令人窒息的暖风以更强大的力量反扑时,这场由“救世主”和“理想家庭”共同编织的美梦,将如何被一场无可避免的风暴,连同那脆弱的风铃一起,彻底撕碎?
【家庭系统观察笔记 01】当“救世主”遇到“理想家庭”:一场完美治愈的心理陷阱 本文故事素材源于对多个家庭心理咨询案例的综合与提炼,旨在探讨家庭系统动力学的普遍模式,而非记录任何特定家庭或个人的真实经历。为保护当事人隐私并严格遵守咨询伦理,文中所有人物、情节、对话及关键细节均经过深度虚构和艺术加工,与任何现实中的个人或家庭均无对应关系。请读者切勿对号入座。本文的重点在于知识分享与人性反思,而非纪实报道。前段时间,我的朋友小A,一位专攻家庭治疗的心理咨询师,接手了一个棘手的案子。委托人是一位母亲,她因为自己15岁的儿子突然表现出强烈的社交回避而焦虑万分——那个曾经活泼的孩子,如今把自己锁在房间里,只通过门缝递纸条与家人交流。心理咨询初期,一切都顺利的不可思议。母亲详尽地描述了家庭的困境。在她零散而充满情绪的讲述中,这个家庭的轮廓逐渐清晰起来:一位追求完美、沉默寡言的建筑师父亲;一个仿佛天生带着情绪雷达的儿子,他总能从父亲放钥匙的声响和母亲的一声叹息里,精准地判断出家里今天的“天气”,并下意识地让自己变成最不占空间、最安静的那件家具;以及她自己,一个在丈夫的沉默和儿子的封闭之间疲于奔命的焦虑核心。当她倾诉完后,小A没有提供任何解决方案,只是精准地复述了她混乱感受中的核心——孤独。那位母亲愣了许久,然后轻声说:“和您谈话,我第一次感觉自己不是一个需要被修理的病人。”那句“不是病人”仿佛是一把钥匙,彻底打开了她信任的闸门。 在接下来的几周里,她不仅将积压多年的烦恼与焦虑倾泻而出,更像一名最虔诚的学生,贪婪地阅读小A推荐的每一本书,笔记本上写满了密密麻麻的心得。她不止一次在咨询结束时,眼中闪着光对小A说:“我感觉自己被治愈了,整个家都好像被照亮了。”而对小A而言,这份全然的信任不只是专业的认可,更像是一剂注入疲惫灵魂的强心针。家庭心理咨询本就是个吃力不讨好的领域,来访者们往往身处痛苦的漩涡,自然会渴望立竿见影的改变;或是出于自我保护的本能,难以在短时间内卸下心防。对于小A这样共情能力极强、甚至到了会过度透支自己来维护关系的理想主义者来说,这种不被信任的消耗是巨大的。因此,这位母亲的出现,就如同在漫长而崎岖的跋涉中,突然遇到了一片水草丰美的绿洲。这片绿洲的意义,很快就远超一份工作。这个家庭的轮廓,像一枚尘封的旧邮票,精准地贴合在他记忆的某个角落。那追求完美的父亲,让他想起自己童年时那个永远无法被取悦的背影;那过度懂事的孩子,简直就是中学时代的他自己,永远在察言观色,生怕行差踏错。“这是命运的安排,”小A在一次与我深夜长谈时,眼中闪着异样的光彩,“有这位母亲的全然信任,我感觉自己像一个拿到时空钥匙的人,终于可以回到过去,对那个无助的小男孩说:‘别怕,我来拯救你了。’这会是一个完美的闭环。”一个完美的救赎故事,一个理想的治愈开端。然而,在心理咨询的地图上,过于平坦顺利的开局,往往指向最危险的悬崖。小A感受到的“自我疗愈”和母亲体验到的“被照亮”,真的是一剂良药吗?或者,这只是这个家庭系统为了自保,上演的一出更精妙的金蝉脱壳?要看穿这层迷雾,我们不能再盯着某一个人看,而需要戴上一副叫做家庭系统动力学(Family Systems Dynamics)的广角镜。戴上它,你会发现,家庭不是一堆积木,而更像一个悬挂在婴儿床上的、由各种小物件组成的风铃。父亲、母亲、儿子,就是风铃上三个相互牵制的挂件。在这个家里,父亲这枚最重的挂件,主动选择静止,他用沉默和疏离,拒绝参与任何摇摆。 但系统的能量不会消失,为了维持整个风铃不至于彻底死寂,母亲就必须过度补偿,她变成了那个最轻、最敏感的铃铛,用加倍的焦虑和不停的摇晃,来填补父亲留下的能量真空。而儿子呢?他悬挂在这“绝对静止”和“疯狂摇摆”之间。一边是冰冷的重压,一边是混乱的噪音。为了不被这两种极端的力量撕碎,他唯一的选择就是——让自己失灵。他把自己变成一个缠绕的、不会响的死结,用这种方式,同时抵抗父亲的静和母亲的动。你看,从来没有独立的问题。儿子的“封闭”,是这个失衡风铃系统下,必然产生的结果。这个系统最狡猾的地方在于它的惯性。它就像一个老旧的中央空调,几十年来,全家都习惯了它吹出的、令人窒息的30度“焦虑暖风”。虽然每个人都汗流浃背,但这毕竟是他们唯一熟悉的温度。突然有一天,儿子用社交回避这个行为,把温度计砸了,警报声大作。这其实是系统内部的一次求救。现在,小A来了。他以为自己是来修理空调的救星,但他没意识到,这个系统太强大了,它不想要被修理,只想快速消除警报。于是,系统巧妙地把他收编了。小A不是修理工,他成了一块被递到母亲手里的“冰毛巾”。 母亲把对丈夫的失望、对儿子的无助,全部转化成对这块“冰毛巾”的依赖和赞美,暂时感觉凉爽了。而小A,则因为这块毛巾精准地贴合了自己童年时渴望被认可的伤口,而感到了前所未有的满足。一个愿打,一个愿挨。母亲将对丈夫和儿子的失望与期待,全部转移到了这位“理想老师”身上;而小A,则将自己对童年缺失的补偿渴望,投射到了这个“理想家庭”上。但冰毛巾总会变热,空调的本质问题没有解决。当暂时的凉爽退去,那股熟悉的、令人窒息的暖风以更强大的力量反扑时,这场由“救世主”和“理想家庭”共同编织的美梦,将如何被一场无可避免的风暴,连同那脆弱的风铃一起,彻底撕碎? -
面向技术人员的招聘方法论:如何量化筛选,告别凭感觉挑人 前段时间我所在的科室拟招聘一两名Web系统开发与支持工程师,这份工作对专业技术的要求不高,但是既需要跟人沟通,又要动手写代码,解决各种网站系统的小毛病或增加点新功能。岗位属于劳务派遣制,社招,薪资8~12k/月,学历要求统招本科及以上。由于硬性门槛较低,招聘公告发出后,我很快收到了95份简历,如何客观公正的选出最匹配的几位候选人进行面试呢,我对此进行了一些思考与探索。一个很直观的想法是,我可以列一张表,明确岗位期望候选人具备哪些能力,然后对着这张表给候选人打分,得分高的候选人进入面试环节。基于这种想法,我很快列出了这个岗位所需要的四项核心能力:沟通与理解能力:岗位要求的核心能力责任心与执行力:岗位性质偏向维护和支持,而不是开发与创新,因此要求候选人具备把分配的事情按时做好、注重细节的责任意识。学习能力与适应性:高校信息系统涉及的技术多而杂,而不是少而精,岗位期望候选人表现出对多种技术的学习和适应潜力基础技术素养:侧重知识的广度和系统性,不需要高深技术,但至少要有基本的概念和学习潜力,能听懂技术指导这四项决定候选人能否满足岗位所需功能,但这样选人只能选出能力最优秀的候选人,不能选出最匹配的候选人。很直观的例子是:一位工作时间长、各方面能力非常突出的甚至有望成为技术总监的人,他这四项的评分肯定很高,但不可能干的长久。故在此基础上着重考虑:稳定性与求职动机:候选人对工作的期望是否与岗位匹配,是否充分了解岗位的性质,求职动机是否清晰务实据此,我们有了一个衡量候选人的抽象标尺,接下来我们需要进一步将抽象转换成具体,将抽象标尺转换成具体的评估角度。我们逐个考虑简历上哪些方面可以体现出这些指标。维度一:沟通与理解能力设想一下web开发行业各个流程的工作内容,与“沟通和理解能力”强相关是需求分析、项目研讨、对接客户、前后端对接、产品设计,如果候选人深度参与过相关的工作,大概率会体现在简历上:项目经历描述中,是否有提及与非技术类型角色(如产品、运营、客户)的沟通协作经验,或软件使用手册的编写经验。权重:高项目经历描述中,是否有提及与其他技术人员的沟通协作经验,或者技术型文档(如接口文档、原型图设计)编写经验。权重:中社团和学生干部经历能说明候选人至少进入过与软件开发完全无关的群体中,能侧面映证这一能力,如果这段经历对候选人意义深刻,大概率也会写上去:是否有学生干部、社团组织、志愿者、活动组织等经历。权重:中其他佐证:自我评价中有提到“擅长沟通,表达能力好”。权重:低教育背景中,是否有文科、管理类或辅修相关课程。权重:低简历本身是否清晰,自我介绍是空洞的缺乏说服力的形容词,还是包含大量更具体的名词和形容词。权重:低当然权重可以根据岗位的需求动态设定,如果是技术密集型的岗位,与非技术类型角色的沟通经验就不是很重要。如果候选人针对某一点的描述特别具体有更强的说服力,也可以适度加分。维度二:责任心与执行力“把事情交给他,我放心”,这或许是对一个同事责任心的最高评价。对于这个偏向支持和维护的岗位,责任心尤其重要。它意味着候选人不仅会完成任务,更会关注交付质量,有始有终。简历上很少有人会写“我责任心不强”,所以我们需要从字里行间寻找证据。候选人对过往工作的描述细节和职业生涯的稳定性,这正是考察责任心的绝佳角度。长期项目的参与情况:候选人只完成过几个月的小项目,还是以年为单位长期接手和负责过某个大项目。在软件开发领域,往往从零刚开始构建的时候比较容易,但对于长期项目,需要投入很多精力充分考虑细节,确保项目能够长期稳定迭代,持续增加新功能,还需要较强的耐性,因此在长期项目中主导开发的候选人更符合这一维度的特点。权重:高完整功能的开发和交付:只写了“负责XX模块开发”,还是写了“独立负责XX模块,通过XX方法,将XX指标从A提升到B”?后者不仅体现了技术能力,更体现了对工作结果的关注和复盘总结的习惯,这是责任心的有力证明。权重:中是否提及“支持”与“维护”类工作:如果一位候选人的简历中主动提及了“系统维护”、“故障排查”、“线上问题跟进与解决”、“技术支持”等职责,说明他对此类工作有清晰的认知且不排斥。这对于一个“开发与支持”岗来说,是非常积极的信号。权重:高项目经历的稳定性:项目太多,职责零碎对于一个长期提供技术支持的岗位来说是个危险信号,这说明候选人可能项目变动频繁,或者从事短期项目外包。权重:中自我介绍是否追求代码规范,是否表现出承担琐碎事情的耐性:权重:低独当一面的承担某个项目的候选人可以适当加分:独立承担过长期的大项目开发或者作为主要负责人参与过。加分:高独立完成过具备完整功能的中小规模项目开发。加分:中维度三:学习能力与适应性高校的信息系统建设往往能追溯到上世纪八九十年代,三十多年积累下来,技术跨度极大、新旧并存。这就要求候选人不能只会“一招鲜”,而是要具备快速学习和适应不同技术环境的能力。技术栈的丰富性:候选人的技能列表只集中在某个特定的方面,还是在不同项目中使用过不同的技术栈(如既用过Vue也用过React)。技术栈丰富度较高的候选人更能洞察到不同技术之间的底层关联,也更容易根据工作需求来使用特定的技术。权重:高技术维度的多样性:候选人不同维度的技术丰富度(前端、后端、数据库、浏览器、Web服务器、网络协议、持续集成、Linux、Docker、Android开发、桌面开发、混合开发等),>=4的候选人比较优秀。权重:高主动学习的证据(个人项目/博客/培训证书/技能证书):是否有GitHub主页并有持续更新的个人项目?是否有技术博客记录学习心得?是否通过业余时间学习并考取了“xx开发者认证”之类的证书?这些都是主动学习、探索新技术的铁证。权重:高适应不同业务领域和工作模式:候选人是否在不同行业(如金融、教育、医疗)工作过?是否经历过从0到1的项目,也维护过庞大的旧系统?是否负责过软件开发中不同的工作环节?这些经历都证明了其强大的适应性。权重:中自我介绍中明确表示喜欢看技术博客/研究新技术/有钻研精神/热爱编程等,虽然是自我介绍,但敢这么写一般候选人对这方面有一定的自信,权重可以稍微高些。权重:中对新技术和新热点有所涉猎,项目经历与高校环境相似度高可以适当加分:对AI编程的了解和使用情况:市面上的AI编程工具已经很多了,利用这些工具可以快速适应不同的开发场景,提升开发效率。加分:中项目经历与高校/政府部门/事业单位关联较大。加分:中维度四:基础技术素养聊完了沟通、责任心和学习能力这些“软实力”,我们再来看看硬功夫。对于这个“Web系统开发与支持工程师”岗位,我们需要的不是造火箭的专家,而是一个能听懂技术指导、能上手修改现有系统、知识面相对均衡的“多面手”。在评估候选人的技术素养时,主要关注知识体系是否系统,基础是否扎实。岗位核心编程技能:前后端和数据库,权重:非常高。前端是只提到jQuery和Bootstrap这种基础的框架,还是有使用Vue、React或Angular及相关UI库的经验是否提及了至少一种后端开发语言(如Java, Python, PHP)。值得注意的是,现在很多前端工程师也会使用Node.js,这完全可以算作满足条件。考虑到目前部门的大部分后端开发场景局限于增删改查和API,后端的要求可以稍微放低些。是否具备编写SQL的能力;只能理解基本的主键外键和索引,还是完全理解数据建模的思想计算机类专业的基础技能:是否接受过系统的计算机教育,绩点情况,是否在实际工作中用到算法、操作系统(多线程、进程间通信、操作系统编程)、计算机网络(通常体现在运维经历中)的知识。权重:高辅助性开发技能:Linux脚本、版本控制、容器部署。权重:中维度五:稳定性与求职动机前面四个维度决定了候选人能不能干,而这最后一个维度,则决定了他愿不愿干、能干多久。这对于一个以支持和维护为核心、强调服务意识的岗位来说,其重要性甚至超过了纯粹的技术能力。在评估这一维度时,我们首先可以做一个快速的“硬性筛选”,排除掉那些核心信息完全不匹配的候选人,比如说:地点不匹配:岗位在北京,意向城市却写的是上海、西安等在北京有稳定住址,但是离单位非常远薪资或能力不匹配:期望薪资远超岗位8-12k的范围工作年限超过8年且技术能力过强学历非常高或者技术能力严重溢出经历或意向不匹配:工作性质与岗位差距过大,比如说做C#开发的、做AI研发的、只做Java的稳定性严重存疑:多次出现不到半年就换工作的情况简历太长,>=4页:不会提炼重点,不尊重招聘者的时间在排除了这些明显不符的候选人后,我们再来细致地从简历中寻找能反映“稳定性与求职动机”的特征:过往工作经历的时长:这是评估稳定性的最直观指标。如果候选人之前的几份工作都持续了两年以上,这无疑是一个极强的积极信号。反之,如果工作经历频繁跳动,每份都未满一年,则需要高度警惕。权重:高职业路径与岗位匹配度:候选人是技术专家,还是多面手?是追求高强度研发,还是偏向业务支持?如果一位候选人的履历充满了“高级开发”、“架构师”、“技术负责人”等title,项目经验也都是高并发、高挑战的研发,那么他来应聘一个支持性岗位,很可能是“降维求职”,稳定性风险极高。相反,如果候选人有过往的“系统维护”、“技术支持”、“实施工程师”等经历,或者长期服务于高校、政府等类似环境,那么他的匹配度和稳定性预期就非常高。权重:高期望薪资与当前薪酬范围的匹配度:虽然很多候选人会写“面议”,但我们可以根据其工作年限、技能水平和当前行业水平做一个大致预判。对于一个8-12k的岗位,一位有5年以上经验、技术栈全面的高级工程师,其期望大概率会超出范围。另外,明确写出期望薪资且与岗位范围高度吻合的候选人,其求职的诚意和务实性就更强。权重:高求职意向的描述:候选人在求职意向中写的是“Web前端高级开发”、“Java开发工程师”还是更宽泛的“Web系统开发”?虽然这只是一个标签,但也能在一定程度上反映出他的自我定位和职业追求。如果其自我定位与岗位描述偏差过大,就需要多加留意。权重:低总结至此,我们构建起了一个五维评估模型。它就像一张精密的滤网,不仅帮助我们识别出候选人的能力长板,更能洞察那些隐藏在字里行间的责任心、学习力和稳定性,从而真正告别凭感觉挑人的困境。有了评估维度,具体如何筛选呢?敬请期待下篇《面向技术人员的招聘方法论:简历筛选三步法》
-
大模型在教育行业中的应用初探——AI驱动科研助手 最近AI大模型这个词真是火遍大江南北,从能写诗作画到编程对话,仿佛无所不能。说实话,在参加这次《中国高校数字化青年工程师研讨会》之前,我对大模型在教育行业能做什么,概念还比较模糊,顶多知道它们能构建各种智能体,帮忙找文献和读文献之类的。但这次研讨会,尤其是我参与的项目,真的让我大开眼界,也对AI如何赋能科研有了全新的认识。研讨会背景:一场硬核的AI+教育头脑风暴这次研讨会由中国高校数字化青年工程师社区组织,汇聚了来自全国各地的青年工程师。主办方旨在推动AI技术与高校数字化转型深度融合,聚焦教学、科研、管理、生活和创新创业五大核心场景。研讨会的形式非常新颖且紧凑:我们被分成5组,每组10人,各抽取一个议题,在短短一天内完成团队破冰、议题研究、方案设计、成果总结,并推出代表进行技术原型和方案的汇报。这不仅考验技术能力,更考验团队协作和快速学习能力。我的研讨会之旅:从小白到“智研图谱”队长我们小组非常幸运(也可能说是挑战巨大哈哈)抽中了议题二:“AI驱动科研助手:智能文献检索与知识图谱构建”。坦白说,拿到题目时我心里有点打鼓,虽然我是队长,但对知识图谱、文献智能检索这些概念也只是略有耳闻。议题二题目说明:科研是高校创新的引擎。面对文献海洋和知识碎片化,AI 能否成为师生的第二大脑?本议题需利用 AI 优化高校科研工作,在高效文献检索、自动摘要、知识图谱等领域制定落地方案。除了信息获取效率外,还包括如何借助 AI 实现跨学科关联、研究趋势分析,乃至智能化的科研选题和成果梳理等。目标是打造服务科研全过程的数字助手。但团队的力量是无穷的!组员们来自不同高校,各有所长。我们迅速投入了激烈的讨论:痛点分析:大家集思广益,很快就科研工作中的普遍痛点达成了共识:信息过载与趋势难把握:文献汗牛充栋,如何快速找到关键信息,把握学科前沿?学科壁垒:不同学科间知识隔阂严重,跨学科合作从何入手?产学研脱节:科研成果如何与产业需求有效对接?技术路径探索:讨论中,大语言模型(LLM)和知识图谱(KG)成了我们关注的焦点。我们意识到,单纯依赖LLM可能会有“幻觉”和知识更新不及时的问题,而知识图谱的结构化优势正好可以弥补。将两者结合,似乎是一条可行的道路。方案构思:基于上述分析,我们提出了一个名为“智研图谱——智能文献检索与知识图谱构建”的解决方案。核心理念就是利用LLM强大的自然语言理解和生成能力,去赋能知识图谱的构建与应用,打造一个贯穿科研全过程的智能助手。功能设计:我们围绕科研人员和高校管理者的需求,设计了三大核心功能模块:趋势分析:通过分析海量文献、专利等数据,洞察学科前沿热点。跨域协作:智能匹配学者、技术,打破学科壁垒,促进合作。机遇导航:连接科研成果与产业需求、基金项目,加速转化。成果总结与汇报:作为队长,我既要参与讨论,也要负责统筹,最后还要和另一位组员一起代表团队上台汇报我们一天的成果。时间虽短,但我们还是尽可能地把技术原型(主要是Demo页面)、方案逻辑和应用场景展示了出来。我对大模型应用在科研中的理解与收获这次研讨会,特别是我们小组的项目,让我对大模型在科研中的应用有了质的飞跃的理解:从“聊天”到“思考辅助”:以前总觉得大模型就是个聪明的“聊天机器人”,能回答问题、写写文案。现在我明白了,大模型在科研领域,更像是一个“思考辅助器”。它不仅能“聊”,还能通过学习海量文献,“看懂”、“理解”并“关联”复杂的科研信息。知识图谱是大模型的“黄金搭档”:如果说大模型是聪明的大脑,那知识图谱就像是为这个大脑构建了一个结构清晰、脉络分明的“知识骨架”。大模型可以从非结构化的文献中抽取实体(如论文、作者、方法、数据集)和关系(如引用、合作),并将其填入知识图谱。这样,知识不再是零散的点,而是相互连接的网络。这大大提升了信息检索的准确性和深度。RAG(检索增强生成)的威力:我们提出的“智研图谱”其实暗合了RAG的思想。当用户提问时,系统先从知识图谱和文献库中检索出最相关的信息,然后将这些信息作为上下文“喂”给大模型,让大模型基于这些“有据可查”的内容来生成答案。这能有效避免大模型“一本正经地胡说八道”(也就是所谓的幻觉),让科研助手更可靠。创新点的挖掘:我们团队提出的“智研图谱”的创新点,我认为在于:LLM驱动的自动化构建:利用LLM的语义理解能力,自动化地从文献中抽取知识,构建和更新知识图谱,大大降低人工成本。多维度的科研服务:不仅仅是文献检索,更拓展到趋势分析、合作者推荐、产学研对接等科研全流程服务。用户视角切入:我们深入思考了科研人员(如博士生小王)和管理者的实际痛点和使用场景,力求方案能落地解决问题。当前的痛点与挑战当然,理想很丰满,现实也有骨感。在设计“智研图谱”的过程中,我们也意识到了许多潜在的挑战:模型幻觉与准确性:如何确保大模型提供的信息是准确无误的,这至关重要。多学科术语统一:不同学科有各自的术语体系,如何让模型准确理解并打通是个难题。数据隐私与版权:科研数据,尤其是未公开的数据,其隐私和版权问题需要妥善处理。大规模与性能:构建覆盖广泛学科的知识图谱,其规模和查询性能都是巨大的挑战。用户信任建立:科研工作者对于工具的严谨性要求极高,如何让他们信任并依赖AI助手,需要时间和实践来检验。未来应用前景:AI科研助手,未来可期尽管存在挑战,但我对“AI驱动科研助手”的未来充满期待。科研效率的革命:AI助手能将科研人员从繁琐的文献检索、筛选、整理工作中解放出来,让他们更专注于创新性思考。个性化科研导航:根据研究者的兴趣和背景,智能推荐研究方向、文献、潜在合作者,甚至辅助生成研究假设。加速知识发现与创新:通过连接不同学科的知识点,AI或许能发现人类研究者难以察觉的隐藏关联,催生新的研究范式和跨学科突破。赋能教育与人才培养:这样的工具不仅能帮助成熟的科研人员,也能极大地辅助研究生、本科生快速入门特定领域,提升科研素养。这次研讨会对我来说,就像打开了一扇新世界的大门。从对AI在教育领域应用的懵懂,到能够和团队一起构想出一个具体的“AI驱动科研助手”方案,并且思考其技术实现和未来前景,这个过程让我获益匪浅。虽然我们的“智研图谱”还只是一个初步的构想,但它点燃了我对这一领域深入探索的热情。路漫漫其修远兮,吾将上下而求索。期待未来能看到更多像“智研图谱”这样的AI工具真正落地,为教育和科研事业贡献力量!
-
当代码遇上AI绘画:图像生成大模型在开发中的妙用初探 预计阅读时间:9-11 分钟“代码改变世界,但‘颜值’同样重要!” 作为开发者,我们常常沉醉于用逻辑和算法构建强大功能,但在用户界面(UI)和用户体验(UX)的美学设计上,却可能感到力不从心。你是否也曾为仪表盘的配色方案而抓耳挠腮?为找不到合适的图标而焦头烂额?或者在与业务部门沟通需求时,苦于无法将页面原型快速具象化?更别提那些对UI有特定美学要求的项目,设计一套风格统一的UI组件背景图,有时简直是一项“不可能完成的任务”。幸运的是,人工智能的浪潮为我们带来了新的可能。近年来,图像生成大模型(如Midjourney, DALL-E, Stable Diffusion等)的惊艳表现,让我们不禁思考:这些强大的“AI画家”,能否成为我们开发工作中的得力助手,帮助我们跨越设计的鸿沟呢?这篇博文,便是我作为一名开发者,带着这些疑问所进行的一次探索性实践与思考。我将聚焦于开发过程中常见的几个设计痛点——仪表盘设计稿生成、应用/模块图标创作、页面设计稿快速草拟、以及UI组件背景图设计。为此,我选取了市面上几款主流的图像生成大模型进行了一系列实际测试,并尝试总结出一些初步的方法和心得。如果你也曾被上述设计难题困扰,或者对AI如何在软件开发中发挥创意潜力充满好奇,那么,这篇文章或许能为你打开一扇新的大门,激发一些有趣的灵感。让我们一起看看,当冰冷的代码逻辑遇上AI的无限想象力,会碰撞出怎样的火花吧!图像生成模型概览与作品对比在探讨如何将图像生成模型应用于开发之前,我们不妨先对几款知名且应用广泛的模型进行测试,以便对它们的使用方法和生成效果有一个基本了解。这里,我们以“小蝌蚪找妈妈四格漫画”为题进行创作。MidjourneyMidjourney 的使用方式类似于命令行工具,核心指令是 /imagine,后接描述性的提示词(Prompt)。可以通过参数如 --ar 控制图片宽高比,--v 指定模型版本。{callout color="#4da1ef"}/imagine prompt: 4-panel comic strip, "Tadpole Looking for its Mother" story. Panel 1: Lost tadpoles. Panel 2: Tadpoles meet goldfish. Panel 3: Tadpoles meet turtle. Panel 4: Tadpoles find frog mother. Cute children's book illustration style, simple lines, vibrant colors. --ar 1:1 --v 7.0{/callout}Midjourney 通常会一次性返回四张候选图片,这种“N张选一”的模式在AI图像生成领域中颇为常见,便于用户快速筛选出满意的结果。从这些作品来看,Midjourney 能够理解图片中需要包含的核心视觉元素,但对于复杂的叙事性提示词,其整体理解和故事连贯性表现尚有不足,生成的漫画系列有时略显混乱,缺乏明确的故事线。为了更细致地控制,我们可以让 Midjourney 仅生成四格漫画中的特定一格。例如,我描述了一个小蝌蚪在月色池塘中的场景,并指定了绘画风格:{callout color="#4da1ef"}/imagine prompt: Panel 1 of a 4-panel comic: A group of cute little black tadpoles with long tails swimming in a clear pond, lily pads in the background. One tadpole looks determined. Empty speech bubble above them. children's book illustration, simple lines, vibrant colors, cartoon style, --ar 1:1 --v 7.0{/callout}总的来说,Midjourney 生成的图片在精美度和细节表现上相当出色,比较符合儿童画的风格,并能按照提示词要求预留对话框空白。不过,小蝌蚪的形象有时略显怪异,这或许与其模型在训练过程中接触了大量抽象或风格化艺术作品有关。ChatGPT (集成DALL-E)ChatGPT 的图像生成功能(通常由DALL-E模型驱动,并受益于GPT-4o等大语言模型的强大理解能力),允许用户通过自然对话的方式来生成图片。提示词: 以“小蝌蚪找妈妈四格漫画”为题创作一副儿童读物画风的四格漫画。ChatGPT 一般一次返回一张生成的图片。生成的漫画在视觉上可能略显粗糙,文字内容往往不准确甚至混乱,但它确实基本还原了故事梗概,并且画风也比较贴合儿童读物的定位。SoraSora 的核心定位是文本到视频 (Text-to-Video) 生成模型,但它同样具备生成静态图片的能力,并且可以直接理解中文自然语言。需要注意的是,Sora 目前的交互方式可能不支持复杂的多轮对话调整。提示词: 以“小蝌蚪找妈妈四格漫画”为题创作一副儿童读物画风的四格漫画。Sora 可以一次性返回多张图片。Sora 生成的漫画中,文字的准确性相对较高,也能较好地呈现故事情节,图像具备一定的观赏性。其主要特点(或可视为局限)在于画风可能相对统一,变化较少。主流图像生成模型特性对比根据笔者的使用体验,ChatGPT 和 Sora 更适合对图像编辑专业度要求不高的用户,其自然语言交互方式非常便捷,适合日常快速出图,对图像的极致精细度或艺术性要求不高。Midjourney 则更受设计类专业人士青睐,他们可以通过反复调整提示词(“刷图”)、尝试不同的关键词和参数组合,来追求富有美感的理想图片。笔者还测试了其他几款主流的图像生成模型,根据交互方式、生成图像特点及使用体验,总结如下表:模型/工具名称模型架构(推测)所属机构交互方式文本生成准确度图像编辑能力ChatGPT (集成DALL-E)两阶段生成/类自回归OpenAI自然语言,支持多轮对话中支持gemini-2.0-flash-preview-image-generation类自回归/扩散模型结合Google自然语言,支持多轮对话中支持SoraDiT (Diffusion Transformer)OpenAI自然语言,支持Remix高支持 (主要指风格迁移等)豆包 (Doubao)去噪扩散字节跳动自然语言,支持多轮对话低支持Midjourney去噪扩散Midjourney关键词&参数,Remix功能强大低不直接支持像素级编辑DALL-E 3 (独立API或特定平台)去噪扩散OpenAI关键词&参数,不支持原生Remix交互中API层面可支持编辑 (需编程)小结: 对于开发过程中的图像生成需求,Sora 在理解复杂需求和中文语境方面表现出强大潜力,尤其适合生成故事性、场景感强的内容。 若需要对现有图片进行较精细的编辑(如图形微调、元素增删),ChatGPT、Gemini 或豆包的(局部)编辑功能则更为实用。Midjourney 虽在艺术创作上独树一帜,但在追求快速、功能性的开发辅助场景中,其学习曲线和操作方式可能不如其他模型直接高效。图像生成应用实践仪表盘设计稿生成模型: Sora提示词: 生成一张PC端的审计可视化仪表盘截图,只包含图表,没有导航栏或者菜单。仪表盘使用中文语言,仪表盘分为左中右三列,每列有2-3张图表,深色科技驾驶舱主题。Remix: 增加仪表盘的科技感和驾驶舱氛围。(注:Remix 指的是对已有图像或生成结果进行二次创作、风格迁移、元素重组或细节调整的过程。)Remix: 将图表替换成更复杂的图表,例如“矩形树图”,“热力图”,“地图”。对于简单的图表,可以在一个卡片里面绘制多个,增加信息密度和视觉冲击力。Remix: 以北大红(由深到浅:#9c0000、#c73535、#d96666、#e99797、#eeb2b2、#f4d4d4)为主题配色,仪表盘改为偏向浅色的风格,图表中的图形增加蓝、绿、黄等其他配色以增加视觉丰富度。应用/模块图标创作模型: Sora提示词: 在一个九宫格中生成家具资产管理系统的系列模块图标,以#94070A作为图标颜色,分别代表:家具建账申请、家具建账确认、家具资产管理、家具调拨申请、家具报废申请、低值家具建账申请、低值家具建账确认、家具盘点、院系家具资产管理。Remix: 继续在一个四宫格中生成家具资产管理系统其他模块的图标,分别为:院系家具盘点、校级家具盘点、院系家具报废管理、校级家具报废管理。生成的图标整体质量相当不错,大部分具有直接使用的潜力。在实际操作中,可以通过多次尝试和调整提示词来获取更贴近需求的图标。若需将生成的PNG图片转换为SVG矢量图,可以尝试使用在线转换工具,例如:PNG to SVG - online-convert.com。应用页面设计稿模型: Sora提示词: 请设计北京大学智能翻译助手的PC端网站页面,该网站不仅支持纯文本翻译,还支持语音实时翻译,网站采用现代简约浅色主题,页面需要带有一定的科技感但是不能太过夸张,在页面中添加一些小元素(图标、logo、卡片纹理背景等)彰显北京大学特色,网站UI风格可参考百度翻译。(并上传一张百度翻译的截图作为参考)Sora 生成的页面布局尚可,但整体设计感和细节处理方面,与专业设计师或开发者手动设计的精细度相比,仍有提升空间。模型: Midjourney指令:{callout color="#4da1ef"}/imagine prompt: UI design for a PC website homepage, "Peking University Intelligent Translation Assistant". Modern minimalist light theme, clean interface. Prominent text input/output areas for translation, language selection dropdowns, a clear microphone icon for voice translation. Subtle background pattern inspired by Peking University's architectural lines (e.g., Boya Pagoda outline). Small, elegant Peking University logo in the header. Tech-inspired icons, professional and academic feel. High fidelity mockup. --ar 16:9 --v 6.0 --style raw{/callout}Midjourney 生成的页面在视觉元素和氛围营造上更为出色,背景设计也颇具创意。然而,对于追求“开箱即用”的开发场景,其生成结果往往仍需大量的人工调整和后期处理才能真正落地。UI组件视觉风格探索模型: Sora提示词: 设计一套完整的网站组件UI视觉稿,包括按钮(primary、success、info、warning、danger)、文字链接、单选框Radio、多选框Checkbox、输入框Input、选择器Select、开关Switch、滑块Slider、时间日期选择器DateTimePicker、表格Table、卡片Card、文件上传Upload、导航菜单、页头,主色为#94070A,另外再设计2-3种辅助配色,确保网站配色协调又不单调。采用现代简约风格,浅色主题,背景是纯白色,PC端1920*1080分辨率。尽管提示词中要求设计一个完整的PC端页面来展示这些组件,但Sora目前直接生成完整、精细的PC端UI组件集合预览图的能力似乎尚有不足。不过,对于单个或小范围组件的风格设计、配色方案探索,它还是能提供不错的参考和灵感。带插图的应用功能摘要模型: Sora提示词:在一个四宫格中设计一个插画集,介绍我校AI教学智能体的实际应用,现代矢量风格的插画,采用渐变扁平设计,色彩要鲜艳、饱和度高,充满动感和积极向上的氛围: 1. 问答型的课程AI助教 2. 学科专业问答工具 3. 古籍OCR识别和整理工具 4. 文献研究助手,帮助阅读各类论文,提供专业解释此场景下,Sora能较好地理解需求并生成风格统一的系列插画,为功能介绍或宣传材料提供了高效的视觉支持。总结与展望通过上述一系列的探索和实践,我们可以清晰地看到,图像生成大模型确实有潜力成为开发者在设计工作中的得力助手。无论是快速生成设计灵感、制作原型草图,还是辅助创作图标、插画和探索UI风格,AI都展现了其独特的优势,尤其是在提升效率和帮助非设计专业背景的开发者跨越美学门槛方面。当然,我们也要认识到,目前这些AI工具尚不能完全替代专业设计师的工作。其生成结果的精细度、可控性、对复杂设计规范的严格遵循以及商业落地的成熟度等方面仍有显著的提升空间。正如本文的初衷——作为一次“初探”,我们更应关注其所开启的可能性,以及如何将其巧妙地融入我们的工作流。未来,随着模型能力的不断增强、算法的持续优化以及相关工具链的日益完善,AI辅助设计无疑将在软件开发流程中扮演越来越重要的角色。对于我们开发者而言,积极拥抱这些新技术,学习如何更有效地运用它们(“提示词工程”等),将是我们提升综合能力、释放创造潜力的关键一步。希望本文的分享能为你带来一些启发。让我们共同期待,代码与AI绘画的融合,能在未来碰撞出更多令人惊艳的火花!
-
ODBC安装及Django配置 预计阅读时间:25-35 分钟。本文包含 macOS 和 Windows 平台的配置方法,您可以根据您的操作系统选择阅读相应部分。实际操作中,软件下载和安装可能需要额外时间。开始之前在开始配置之前,我们先简单了解几个基本概念,这会让你对接下来的操作更有数。什么是 ODBC?我为什么需要它?ODBC (Open Database Connectivity):你可以把它想象成一个通用的“翻译官”或“适配器”。很多不同的应用程序(比如我们这里的 Python/Django)想要和各种不同的数据库(比如 SQL Server、Oracle、MySQL 等)“对话”。ODBC 提供了一套标准的接口(API),让应用程序可以用一种统一的方式来请求数据,而不用关心底层数据库的具体实现细节。为什么需要? 对于某些数据库(尤其是像 SQL Server 这样的商业数据库),Python 的数据库驱动(比如 pyodbc 或 Django 使用的 mssql-django 后端间接依赖的驱动)会通过 ODBC 来与数据库通信。ODBC 驱动程序由数据库厂商(如微软)或第三方提供,并安装在你的操作系统上。为什么 Java 连接数据库好像不太需要 ODBC,但 Python 有时需要?Java 有 JDBC (Java Database Connectivity):Java 生态系统中有其自己的一套标准接口 JDBC。数据库厂商通常会提供纯 Java 的 JDBC 驱动程序,这些驱动程序直接实现了与数据库通信的协议,所以它们不依赖操作系统层面的 ODBC。Python 的情况:Python 也有很多数据库的直接驱动程序(比如 psycopg2 for PostgreSQL, mysqlclient for MySQL),它们可能不依赖 ODBC。但对于 SQL Server,一种常见的连接方式就是通过 ODBC。Django 在连接 SQL Server 时,其后端库(如 mssql-django)通常会利用系统上已安装的 ODBC 驱动。本文会用到哪些 ODBC 相关程序/驱动?在 macOS 上连接 SQL Server:我们会使用 unixODBC:一个开源的 ODBC 管理器,相当于 Windows 上的 ODBC 数据源管理器。以及 FreeTDS:一个开源的驱动程序,让 macOS/Linux 系统能够连接到 SQL Server。在 Windows 上连接 SQL Server:我们会使用 Windows 系统自带的 “ODBC 数据源管理器”。以及微软官方提供的 “ODBC Driver for SQL Server” (例如 ODBC Driver 17/18 for SQL Server)。关于 Oracle 连接:本文后续展示的 Django 连接 Oracle 的示例,将采用 Oracle 特有的连接字符串方式,它不依赖于我们前面为 SQL Server 配置的 ODBC,而是通过 Django 的 Oracle 后端直接与 Oracle 客户端库(如果需要)或数据库通信。简单来说,ODBC 就像一座桥梁,帮助我们的 Python/Django 应用连接到特定类型的数据库。接下来的内容,我们将一步步教你如何在你的 Mac 或 Windows 系统上搭建这座“桥梁”来连接 SQL Server,并配置 Django 项目使用它。Mac系统连接SQLServer本章节描述的在macOS上使用 unixODBC 和 FreeTDS 连接SQL Server的配置流程,其核心原理和步骤与在Linux系统上操作非常相似。主要区别在于软件包的安装命令(例如,您会使用 apt、yum 或 dnf 而不是 brew)以及配置文件的默认存放路径。理解了macOS的配置过程后,您可以触类旁通地在Linux上完成类似配置。Mac:系统版本Sonoma14.5;brew4.4.6SQLServer:2019版本(容器镜像为mcr.microsoft.com/mssql/server:2019-latest)brew install unixodbc brew install freetds open -e /opt/homebrew/etc/odbcinst.ini # 编辑文件 # 在文件末尾输入下面的内容,用来将FreeTDS注册到unixodbc中 [FreeTDS] Description=FreeTDS Driver Driver=/opt/homebrew/lib/libtdsodbc.so open -e /opt/homebrew/etc/odbc.ini # 编辑文件 # 在文件末尾输入下面的内容,请根据你实际要连接的数据库配置Server、Port和Database # 如果你使用的SQLServer版本较老,TDS_Version可尝试小一点的版本,例如7.0 [djangoadmindemo] Driver=FreeTDS Server=127.0.0.1 Port=7011 Database=djangoadmin TDS_Version=7.4 你可以使用下面的命令来验证ODBC是否配置正确export ODBCSYSINI=/opt/homebrew/etc export ODBCINI=/opt/homebrew/etc/odbc.ini odbcinst -q -s # 如果配置正确,会列出你配置的所有数据源名称 isql -v djangoadmindemo sa ******** # 使用指定的用户和密码连接djangoadmindemo数据源Django项目配置文件中,数据库连接配置的OPTIONS参考下面的写法DATABASES = { 'default': { ...... 'OPTIONS': { "driver": "FreeTDS", 'dsn': "djangoadmindemo", }, } }Windows系统连接SQLServerWindows:win10专业版SQLServer:2019版本(容器镜像为mcr.microsoft.com/mssql/server:2019-latest)驱动下载和安装点击下面的链接,选择合适的版本进行下载:Download ODBC Driver for SQL Server - ODBC Driver for SQL Server | Microsoft Learn安装完成后,按win+R,输入odbcad32,打开ODBC数据源管理程序:点击添加,如果你的SQLServer版本比较新,就选择ODBC Driver 18 for SQL Server,如果很老,就选择SQL Server。注意:服务器的IP和端口之前请用逗号,分割,不要用冒号:一直点下一步,最后点击测试数据源。如果提示“证书链是由不受信任的颁发机构颁发的。”,可以返回上一步,勾选“信任服务证书”Django项目配置文件中,数据库连接配置的OPTIONS参考下面的写法,driver对应上图的驱动程序,dsn对应上图的名称。DATABASES = { 'default': { ...... 'OPTIONS': { "driver": "ODBC Driver 18 for SQL Server", 'dsn': "djangoadmindemo", }, } }连接ORACLEOracle:23版本(容器镜像为gvenzl/oracle-free:23)(注:Django5.0和Django4.X都要求Oracle版本为19c或更高)请参考下面的示例进行配置: 'default': { 'ENGINE': 'django.db.backends.oracle', 'NAME': ( "(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=162.105.132.198)(PORT=7012))" "(CONNECT_DATA=(SERVICE_NAME=FREEPDB1)))" ), # ORACLE的连接描述,如果你配置了tnsnames.ora,你可以在这里只指定服务名的名称 'USER': 'djangoadmin', 'PASSWORD': '**********', }
-
Django Admin安装及入门教程 预计阅读时间:30-45 分钟。如果您是新手并跟随步骤实际操作,可能需要更多时间。开始之前在正式踏上 Django Admin 的学习之旅前,我们先花几分钟明确几个基本问题。这会帮助你更好地理解 Django Admin 是什么,它能做什么,以及它在整个 Django 生态中的位置。同时,我会用最简洁的语言告诉你使用 Django Admin 的核心思路。Django Admin有什么用?简单来说,Django Admin 是一个非常强大且方便的工具,它能帮你快速生成一个功能完善的数据管理后台。想象一下,你的网站或应用需要管理用户信息、用户权限、下拉菜单的选项、网站的公告。在传统开发模式下,这些都需要你手动编写前端页面、后端接口逻辑,并处理数据的增删改查。而使用 Django Admin:你几乎不需要编写任何前端界面代码(HTML, CSS, JavaScript)或复杂的后端视图逻辑。你只需要专注于定义你的数据模型 (Models) —— 也就是告诉 Django 你的数据长什么样。然后通过一些简单的配置 (Admin classes),Django Admin 就能自动为你生成一个专业的、可定制的管理界面。管理员可以直接在这个界面上进行数据的增、删、改、查操作,无需开发人员直接操作数据库,既安全又高效。它特别适合数据驱动的管理任务。如果你的业务系统主要就是对各种数据对象进行维护,或者你需要在主业务系统之外快速搭建一个后台管理工具来维护一些配置数据、辅助数据,那么 Django Admin 会是一个极佳的选择。当然,对于那些业务流程非常复杂、交互逻辑高度定制的应用,Django Admin 可能不是直接的解决方案,但它仍然可以作为系统的一部分发挥重要作用。Django和Django Admin有什么关系?首先,你需要知道 Django 是一个高级的 Python Web 框架。它鼓励快速开发和简洁、实用的设计。你可以用 Django 来构建各种复杂的 Web 应用,从简单的博客到大型电商平台,甚至是你正在使用的业务系统(如果它是 Python 开发的话)。Django 负责处理请求、响应、数据库交互、模板渲染等 Web 开发的方方面面。Django Admin 则是 Django 框架内置的一个强大应用(app)。你可以把它想象成 Django 这个“大工具箱”里的一件“超级工具”。当你创建一个 Django 项目时,Admin 功能就已经准备好了,你只需要激活并配置它,就能享受到它带来的便利。它充分利用了 Django 的模型层 (Models)、表单 (Forms)、认证授权 (Auth) 等核心组件,是 Django “ Batteries included ”(自带电池,开箱即用)理念的完美体现。所以,Django 是一个全功能的 Web 框架,而 Django Admin 是这个框架中一个专注于快速生成数据管理后台的子系统或应用。Django Admin的核心用法如果你想用一两句话理解 Django Admin 的核心用法,那就是:定义你的数据长什么样 (Models):用 Python 代码描述你想要管理的数据结构(比如一个“学生”信息表,包含姓名、学号、班级等字段)。告诉 Admin 如何展示和管理这些数据 (Admin Classes):通过简单的配置,告诉 Django Admin 你希望在管理后台如何显示这些“学生”信息,比如列表页显示哪些字段、哪些字段可以搜索、哪些字段可以作为筛选条件等。就这么简单! 完成这两步,Django Admin 就会自动为你生成一个功能齐全的网页界面,你可以通过浏览器访问它,对“学生”数据进行添加、查看、修改和删除操作,完全不需要你写一行 HTML 或 JavaScript!接下来的教程,就会带你一步步实践这个过程。Conda安装方法conda是Python的包管理和环境管理软件,可以让你的电脑安装多个Python环境,这样你可以同时开发多个Python项目而不冲突。这是conda的官方网站,根据自己的系统下载相应的安装包并进行安装即可:Download Now | Anaconda (如果需要图形页面就安装Anaconda,不需要就安装Miniconda)安装成功后,你可以打开命令行并运行conda env list 来验证你是否安装成功,如果安装成功,这条命令会列出一个名为base的Python环境,它是conda安装后自动创建的Python环境。Conda用法下面列出了一些常见的conda命令。你可以先跳过这部分,等用到的时候再回来查查看。环境管理命令创建新环境:conda create --name myenv激活环境:conda activate myenv ,激活名为 myenv 的环境,使其成为当前会话的活动环境。此时你在命令行中的python会默认为myenv的python,pip安装的包也只会在myenv下安装。停用环境:conda deactivate ,停用当前激活的环境,返回到base环境或系统默认环境。列出所有环境:conda env list ,列出所有已创建的 Conda 环境。删除环境:conda remove --name myenv --all包管理命令注:你也可以用python自带的包管理工具pip,不一定要用conda安装包:conda install package-name在当前激活的环境中安装名为 package-name 的软件包。更新包:conda update package-name更新当前环境中名为 package-name 的软件包到最新版本。删除包:conda remove package-name 从当前环境中删除名为 package-name 的软件包。列出已安装的包:conda list列出当前环境中所有已安装的软件包及其版本信息。其他有用命令搜索包:conda search package-name搜索 Conda 仓库中可用的名为 package-name 的软件包。更新 Conda 自身:conda update conda更新 Conda 包管理器到最新版本。导出环境:conda env export > environment.yml将当前环境的配置信息导出到一个 environment.yml 文件中,可以用于在其他系统上重建环境。从文件创建环境:conda env create -f environment.yml使用 environment.yml 文件创建一个新的 Conda 环境。项目创建下面以项目名为LemisManage为例,请根据实际项目名称进行替换。创建项目环境:conda env create -f environment-common.yml -n LemisManage -n后面的是环境名称。在Pycharm中创建项目:项目创建后,你可以尝试直接运行项目,来验证项目及项目环境是否正常,如果正常,访问网站根路径你可以看到这样的页面:项目配置修改项目运行的端口号和绑定的IP点击pycharm右上角的Edit Configurations:在项目运行配置页面可以配置绑定的IP和端口号,如果你想绑定本机拥有的所有IP,就将图中的localhost改为0.0.0.0:项目配置文件项目配置文件位于LemisManage/settings.py (相当于Springboot的application.yml),你可以像正常的python文件一样在里面编写Python代码,这个文件里面的全局变量会作为配置项。下面列出了一些通用的配置,请你在配置文件中找到这些配置项并根据实际情况进行替换/新增: # 指定哪些主机名或域名可以合法地向 Django 应用发送请求 ALLOWED_HOSTS = ['*'] if DEBUG else [] INSTALLED_APPS = [ # 本项目的应用 # 第三方应用 "import_export", "simpleui", # Django自带应用 "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", ] # 指定项目默认的语言代码,Django自带国际化支持,例如Django Admin就支持很多语言 LANGUAGE_CODE = 'zh-hans' # Django也带有多时区的支持,这个配置项告诉Django本地的时间是什么时区 TIME_ZONE = 'Asia/Shanghai' # 不启用时区支持,如果你的应用只在中国使用,放心把这个关掉,省很多事 USE_TZ = False # 日志配置 LOGGING = { 'version': 1, 'disable_existing_loggers': False, # 是否禁用未在此处声明的所有日志记录器 'handlers': { 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'level': 'WARNING', # 改为DEBUG可以看到执行的SQL 'handlers': ['console'], 'propagate': False, }, }, }数据库配置,默认情况下Django会使用SQLite作为数据库,如果你使用Django Admin来从头构建你的Web应用,那你完全可以直接使用默认的SQLite数据库,对于用户量最多为几百的情况是完全够用的。下面以SQLServer为例进行展示,OPTIONS用于配置数据库驱动,这和你的操作系统和连接的数据库有关,具体请参考另一篇文章《ODBC安装及Django配置》,你也可以参考Django数据库配置(Django官方文档,包含Django官方支持的PostgreSQL、MariaDB、MySQL、Oracle、SQLite)的配置方法:DATABASES = { 'default': { 'ENGINE': 'mssql', 'NAME': 'djangoadmin', 'USER': 'sa', 'PASSWORD': '**********', 'HOST': '127.0.0.1', 'PORT': '7011', 'OPTIONS': { ...... }, } }配置完成后,请启动Django项目,Django会检查配置文件是否正确,数据库连接是否正常。数据库初始化Django默认安装的应用(可以在settings.py的INSTALLED_APPS中看到)提供了一些功能,这些功能需要创建数据表才能正常使用,请在Pycharm中打开终端:执行命令(注意,下面的命令会自动在数据库中创建表:auth_group、auth_group_permissions、auth_permission、auth_user、auth_user_groups、auth_user_user_permissions、django_admin_log、django_content_type、django_migrations、django_session)pip install django==5.0.6 --force-reinstall # 最新的5.1版本太新了,不兼容mssql后端 python manage.py makemigrations python manage.py migrate出现若干表示成功的OK提示:创建超级用户并登录在Pycharm的终端中,输入命令python manage.py createsuperuser ,按照提示输入信息访问/admin,登录到管理页面成功!创建你的应用和模型如果你正在使用Django Admin创建一个全新的数据管理应用,需要创建新的数据表,你可以这样做:在Pycharm的终端输入命令python manage.py startapp myapp以创建一个应用,myapp是应用名称,一个应用对应了一个业务。打开settings.py ,将应用添加在INSTALLED_APPS中:INSTALLED_APPS = [ # 本项目的应用 "myapp", ...... ]打开myapp/apps.py ,为应用添加一个人类友好的名字:from django.apps import AppConfig class MyappConfig(AppConfig): default_auto_field = 'django.db.models.BigAutoField' name = 'myapp' verbose_name = "我的应用"打开myapp/models.py ,在这个文件中定义数据模型,一个数据模型对应一张数据表:from django.db import models # Create your models here. class Document(models.Model): doc_num = models.CharField("文档编号", max_length=32, db_index=True) # db_index=True表示为这个字段建立数据库索引 name = models.CharField("文档名称", max_length=50, blank=True, db_index=True) # blank=True表示用户填写表单时,这个字段不是必填项 count = models.PositiveIntegerField("数量", null=True, blank=True) # null=True表示在数据库表中,这个字段允许为NULL num_pages = models.PositiveIntegerField("页数", null=True, blank=True) storage_location = models.CharField("存放位置", max_length=200, blank=True, db_index=True) create_time = models.DateTimeField(verbose_name="创建时间", auto_now_add=True) # auto_now_add表示创建对象时,自动将这个字段赋值为当前时间 class Meta: verbose_name = "文档" # 单数名称 verbose_name_plural = verbose_name # 复数名称 # 用于定义一个人类友好的字符串表示 def __str__(self): if self.name: return self.doc_num + " " + self.name else: return self.doc_num 若你不定义主键,Django会默认添加一个名为id的自增整数主键。创建好模型后,运行下面的命令,将模型同步到数据库中。python manage.py makemigrations # 生成描述模型变更的迁移文件(在应用的migrations文件夹中) python manage.py migrate # 读取迁移文件,同步到数据库迁移完成后,你可以在数据库中看到自动创建的数据表。模型默认的数据表名应用名_模型名小写 ,你可以在模型类的Meta中自定义db_table = "数据表名"将模型注册到Django Admin中打开myapp/admin.py,编写如下代码:from django.contrib import admin from .models import Document # Register your models here. @admin.register(Document) class DocumentAdmin(admin.ModelAdmin): list_display = ("doc_num", "name", "count", "num_pages", "storage_location", "create_time") # 按顺序展示这些列 search_fields = ("doc_num", "name") # 适合进行文本搜索的字段 list_filter = ("storage_location", ) # 适合用下拉菜单进行过滤的字段 list_per_page = 10 # 每页展示的数据条数你可以在Django管理站点找到更多的ModelAdmin配置访问/admin (你不需要手动重启服务器,只需刷新页面即可,因为Django检测到你修改了代码会自动重启)根据数据表反向得到模型的定义如果你已经有了一套成熟的web系统,只想用Django Admin实现数据管理功能,不需要创建新的数据表,你可以这样做:使用命令python manage.py inspectdb [数据表名] ,例如python manage.py inspectdb myapp_document ,然后Django会输出下面的内容:# This is an auto-generated Django model module. # You'll have to do the following manually to clean this up: # * Rearrange models' order # * Make sure each model has one field with primary_key=True # * Make sure each ForeignKey and OneToOneField has `on_delete` set to the desired behavior # * Remove `managed = False` lines if you wish to allow Django to create, modify, and delete the table # Feel free to rename the models, but don't rename db_table values or field names. from django.db import models class MyappDocument(models.Model): id = models.BigAutoField(primary_key=True) doc_num = models.CharField(max_length=32, db_collation='Chinese_PRC_CI_AS') name = models.CharField(max_length=50, db_collation='Chinese_PRC_CI_AS') count = models.IntegerField(blank=True, null=True) num_pages = models.IntegerField(blank=True, null=True) storage_location = models.CharField(max_length=200, db_collation='Chinese_PRC_CI_AS') create_time = models.CharField(max_length=27) class Meta: managed = False db_table = 'myapp_document'你可能需要对这些代码进行如下修改,以让Django Admin更好地理解和展示你的数据表:为每个字段添加一个人类友好的名称verbose_name = ""检查这些字段是否是正确的,例如上面的create_time应该是models.DateTimeField ,而不是models.CharField 。调整字段的blank = True/False ,如果它是必填的,设为False,如果不是必填的,设为True如果你保持Meta中的managed = False ,在执行manage.py makemigrations命令时不会自动检测这个模型的修改,也就是说Django不会将你在代码中对模型进行的修改同步到数据库中,你可以先保持这个设置,等你熟悉Django以后再尝试将其改为True。如果你的表存在外键,你需要手动设置models.ForeignKey的on_delete属性,例如models.ForeignKey(on_delete=models.CASCADE) ,表示这是一个级联删除的外键。然后你可以参考前面的教程,将模型注册到Django Admin中,实现数据管理的功能。本教程的项目代码{anote icon="fa-download" href="https://www.liuyh.com/download/file?cid=311" type="info" content="LemisManage.zip"/}
-
多模态大模型文本识别和理解能力测评 最近许多业务系统都提出了涉及图片中文本识别和理解的需求,主要集中在这几点:通过OCR识别票证,输出结构化信息识别文档中图片的内容(多为表格),或者是直接从文档扫描件提取文档观察了一下最新的多模态大模型(MLLM),MLLM有图片理解能力可以直接结构化输出,一些优秀的大模型对中文的支持也不错。结合实际需求,我选取了几款大模型进行了一些测评,下表是我得到的测评结果,详细过程可见后文。 票证提取文档理解文档提取古籍手写文本日常生活类gemini-2.5-pro-preview-03-25⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐gemini-2.5-pro-preview-05-06⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐gemini-2.5-flash-preview-04-17⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐gemini-2.5-flash-preview-04-17(深度思考)⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐claude-3-7-sonnet-20250219⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐claude-3-7-sonnet-20250219(深度思考)⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐o4-mini⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐o3⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐gpt4.1⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐通义千问-QVQ-Max(2025.3.25快照版本)⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐通义千问VL-Max(2025.4.8快照版本)⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐通义千问2.5-VL-72B⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐❌⭐⭐⭐⭐⭐⭐⭐⭐通义千问2.5-VL-32B⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐InternVL3-14B⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐星级主要用来反应模型之间的相对水平,是基于经验和手动的测评结果得到的,仅供参考,不具备学术上的严谨性。一些具备OCR能力,但未深入测试的MLLM:通义千问-QVQ-72B-Preview:模型输出的内容极度倾向数学推理,基本无法输出遵循指令的内容。根据官方的说法,其在识别人员、动物或植物等基本识别任务上,QVQ 相比 Qwen2-VL-72B 并没有显著提升,因此不做测评。通义千问VL-OCR(2025.4.13快照版本):无法输出结构化的文本,票证、古籍和手写文字的识别效果也很一般,无法理解文档,文档提取的效果较差。更新:2025.5.8加上了gemini-2.5-pro-preview-05-06模型。测评结果注解: 票证提取文档理解文档提取古籍手写文本日常生活类gemini-2.5-pro-preview-03-25出租车票一些错误,行程单极少错误完全正确复杂表格提取出的排版有些问题基本一致,我非专业人士,无法评估排版的合理性完全一致完全正确,对表情包的解读也很到位gemini-2.5-pro-preview-05-06出租车票一些错误,行程单极少错误完全正确复杂表格提取出的排版接近完全正确基本一致,我非专业人士,无法评估排版的合理性手写笔记有一些错误完全正确,对表情包的解读也很到位gemini-2.5-flash-preview-04-17出租车票和行程单错误非常多没有发现企业团体会员也满足条件复杂表格提取出的排版较大问题史记提取的不错,后汉书错误很多英语手写笔记的识别错误较多表情包的解读完全错误gemini-2.5-flash-preview-04-17(深度思考)出租车票的错误较多,行程单少许错误未能识别出弃权票复杂表格提取出的排版较大问题史记提取的不错,后汉书错误很多打油诗有几个字识别错误表情包的解读不完全正确claude-3-7-sonnet-20250219出租车票和行程单错误较多,结算票据有少量错误没有发现企业团体会员也满足条件复杂表格提取出的排版较大问题史记和后汉书都有较多错误打油诗错误较多,手写笔记一些错误表情包的解读基本错误claude-3-7-sonnet-20250219(深度思考)出租车票和行程单错误较多,结算票据有少量错误完全正确复杂表格提取出的排版有些问题史记和后汉书都有较多错误打油诗和手写笔记都有一些错误表情包的解读基本错误o4-mini出租车票和行程单错误非常多完全正确复杂表格提取出的排版较大问题史记和后汉书都有较多错误并有缺失手写笔记有一些错误表情包的解读完全错误o3出租车票和行程单和结算票据错误非常多完全正确复杂表格提取出的排版较大问题史记有较多错误,后汉书无法提取打油诗和手写笔记都有一些错误尝试解读表情包时多次无法响应,可能是思维链太长gpt4.1出租车票和行程单错误较多,结算票据有少量错误对投票文档的理解有很大错误复杂表格提取出的排版较大问题史记有较多错误,后汉书无法提取打油诗少量错误,手写笔记一些错误表情包的解读完全错误通义千问-QVQ-Max(2025.3.25快照版本)出租车票的错误较多,行程单少许错误对投票文档的理解有很大错误复杂表格提取出的排版较大问题史记有较多错误,后汉书基本一致基本一致,手写英文笔记有少量词组片段笔记遗漏表情包的文化创意看懂了,但是表情包的情感分析欠佳通义千问VL-Max(2025.4.8快照版本)出租车票的错误较多,行程单极少错误,结算票据有一些错误对投票文档理解有误,输出不完整;没有发现企业团体会员也满足条件复杂表格提取出的排版非常混乱基本一致打油诗错误较多,手写笔记一些错误表情包的解读基本错误通义千问2.5-VL-72B出租车票的错误较多,行程单极少错误对投票文档的理解有很大错误;没有发现企业团体会员也满足条件复杂表格提取出的排版有些问题未能输出任何有效内容基本一致,手写英文笔记有少量词组片段笔记遗漏表情包的解读基本错误通义千问2.5-VL-32B出租车票一些错误,行程单极少错误对投票文档的理解有很大错误拨款通知单表格提出有些问题,复杂表格提取出的排版有些问题能提取出主要内容,但结构与原文有明显出入有一些手写中文字识别错误表情包的解读完全错误InternVL3-14B出租车票的错误较多,行程单极少错误,结算票据有一些错误对投票文档的理解有很大错误;没有发现企业团体会员也满足条件拨款通知单表格提出有些问题,复杂表格提取出的排版有些问题史记有较多错误,后汉书无法提取打油诗少量错误,手写笔记一些错误表情包的解读完全错误;未能得出电影名称前沿MLLM对比所属机构模型名称开源参数量深度思考发布日期Googlegemini-2.5-pro-preview-03-25❌❓✅2025.3.26 gemini-2.5-pro-preview-05-06❌❓✅2025.5.6 gemini-2.5-flash-preview-04-17❌❓支持切换2025.4.18Anthropicclaude-3-7-sonnet-20250219❌❓支持切换2025.2.25OpenAIo4-mini❌❓✅2025.4.17 o3❌❓✅2025.4.17 gpt4.1❌❓❌2025.4.14Alibaba通义千问-QVQ-Max(2025.3.25快照版本)❌❓✅2025.3.28 通义千问VL-Max(2025.4.8快照版本)❌❓❌2025.4.8 通义千问-QVQ-72B-Preview✅72B✅2024.12.25 通义千问VL-OCR(2025.4.13快照版本)❌❓❌2025.4.13 通义千问2.5-VL-72B✅72B❌2025.1.28 通义千问2.5-VL-32B✅32B❌2025.3.25OpenGVLabInternVL3✅78B、14B等❌2025.4.15深度思考为✅的模型就是推理模型。推理速度是基于个人经验给出的相对评价。测试图片票证提取(提示词:尽量详细的提取图片中的票证信息,并以json格式输出)这个出租车票的字迹十分模糊,车号的后面一大截被完全遮挡,无法识别,大模型很容易产生幻觉。这个行程单不仅看着让人头晕目眩,而且表格的排版与实际印上去的字有一定的错误,信息量较大但又很简短,需要有很强的理解能力才能准确识别。一张比较常规的票据,数字和英文字体之间有一定的交叠,有一定的识别难度。一张国外的发票,排版和中文发票有明显区别,发票上有老师的个人签名,十分潦草,可以用来测试模型的中文手写体识别能力。比较简单的身份证识别。身份证的字都比较清楚,排版也固定。文档理解提问:识别图中的投票结果并以JSON格式输出识别投票结果,看起来比较简单,实际上需要模型能准确理解表格的排版,并合理猜测一些不太符合预期的人类手写标记。提问:有哪些交费档次平均下来每人交纳200元人民币,有效期是多长?这需要模型理解表格,而且这个问题有一点小陷阱,企业团体会员折合下来也符合这个标准,模型也应当能捕捉到文档提取(提示词:以markdown或html格式输出图片中的文档,尽量保证输出内容完整,排版与图片中保持一致)下面的图片,要求模型以markdown或html格式输出图片中的文档,而不只是用json输出结构化信息。下面的图片,要求模型以markdown或html格式输出图片中的表格,表格排版非常复杂。古籍提取(提示词:以markdown或html格式输出图片中的古籍,尽量保证输出内容完整通畅)史记-卷八后汉书手写文本(提示词:以markdown或html格式输出图片中的手写文本,尽量保证输出内容完整通畅)我自己随便写的打油诗英语手写笔记日常生活类图片理解提示词:这张网络流行图片的创意出自什么作品,作为表情包有什么含义?(这张图片的创意来源于苏轼的散文名篇 《记承天寺夜游》, 最常见的用法是模仿苏轼半夜找朋友,用来在深夜或者任何时候突然呼叫某个朋友)提示词:这是什么电影(《幽灵公主》,由吉卜力工作室出品,宫崎骏导演)
-
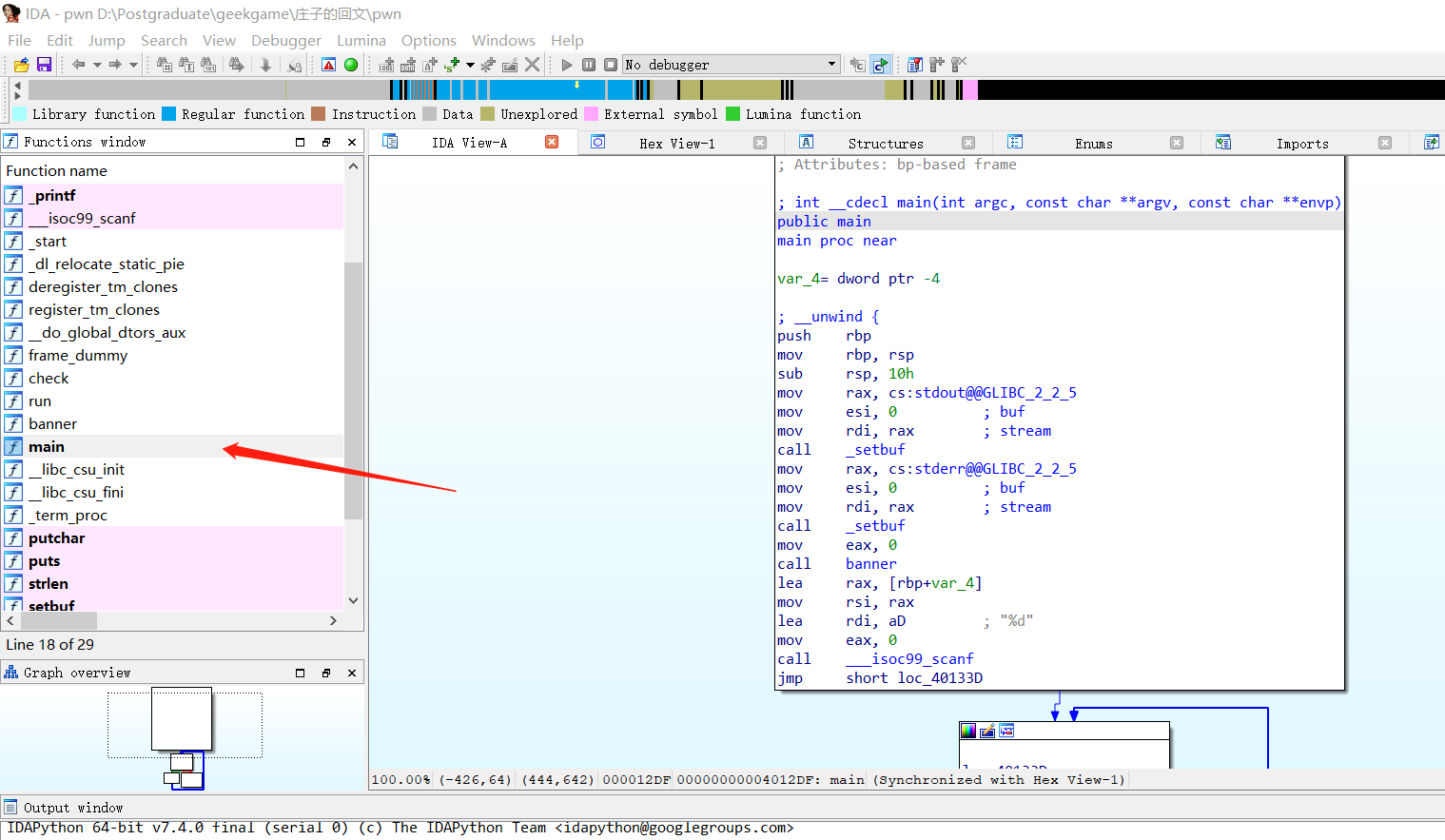
庄子的回文——从零开始的入门级64位ROP 背景介绍前段时间,我们学校组织了一场校内的以推广CTF赛事为主的网络安全比赛。当时其实并没有很想参加,不过在舍友的安利之下 ::(汗),我于第二天加入了内卷洪流之中。 不过出乎意料的,比赛的赛题设计的很有意思,也很适合我这种网络安全知识面比较广但是没做过实操的人。就这样我开启了我的网络安全修炼之路。比赛过程中,我所用到的大部分的知识都属于现学现卖,最终也是取得了不错的成绩,于是,我也有了写博客的想法。希望能为后人种一种树。本篇文章作为入门级Pwn赛题的讲解,只需读者掌握部分计算机学科基础知识即可。本篇文章只关注入门的内容,如果你是高手可能会觉得很无聊。Pwn是什么?通常是要利用程序中的特定漏洞,构造特定字符串(也称payload)输入程序中,以达到控制目标主机的目的。通常这种题目都相当直白,直接扔给你一份编译后的可执行程序,然后给你一个ip地址和端口,这个端口上跑的就是这个可执行程序,你要做的就是在本地分析出这个可执行程序中存在的漏洞,并且巧妙构造一份字符串,输入给这个端口,然后如果构造正确的话,就可以利用这个端口控制远程主机。发现漏洞一般都是比较简单的事情,然而,想要利用这个漏洞控制远程主机,需要非常心灵手巧才行 :@(暗地观察) 。因此这类题上手难度较大,不过一旦成功往往会有一种巨大的成就感。题目{card-default label="庄子的回文" width=""}在《庄子》中,逍遥而遊的自由存在内蕴着一个逍遥主体与 Flag 之间的深刻而复杂的关系,这一关系必须置于一个回文过程中来理解。逍遥作为艰苦的历程,其要义在于它经由对自身的出离而与异于自身的他者相遇,并与他者共同构成彼此相聚的整体,在此整体中确证自身且返回自身。《庄子》对逍遥的诗意言说方式本身,并不掩盖逍遥观念自身的过程本质。撇开了如此艰苦的历程,逍遥就会成为毫无内容的仅仅溢于言表的虚幻的托辞。逍遥必须回到其艰苦而丰富的展开过程,才是真实的。 ——郭美华请把字符串交给庄子,设法让庄子在计算回文串时,在服务器上执行代码或命令,读取文件系统中某处存储的 Flag。你可以 下载本题的程序点击 “打开/下载题目” 将打开网页终端,你也可以通过命令 nc prob05.geekgame.pku.edu.cn 10005 手动连接到题目PS: 上述指令其实就是和prob05.geekgame.pku.edu.cn的10005端口建立TCP连接,因为服务器可能关闭,所以上述IP端口可能失效{/card-default}做出本题需要掌握的知识{message type="info" content="1、x86汇编及部分x64汇编知识2、python语言及pwntools的基本用法3、gdb动态调试和ida静态调试4、C语言和Linux操作系统的基本知识"/}程序安全保护信息与实验环境{collapse}{collapse-item label="程序安全保护信息" open} 以下是程序安全保护信息,用checksec指令进行查看: ❗ 本题程序没有开启CANARY保护{/collapse-item}{collapse-item label="实验环境" open}主机:Win10 专业版 19042.1052虚拟机:Kali Linux 2021.1 amd64{/collapse-item}{/collapse}IDA的简单使用——反汇编和反编译可执行文件首先需要下载一个静态分析利器ida,这个软件可以对可执行文件进行反汇编,甚至可以反编译成比较容易看懂的C语言代码。这里给出一个下载链接,读者可根据自身需要选择: {anote icon="fa-download" href="https://www.jb51.net/softs/757010.html" type="secondary" content="IDA Pro 7.5破解版"/}安装成功后,主要有两个程序,一个是IDA Pro 7.5 SP3,另一个是IDA Pro 7.5 SP3 x64,前者是用来分析32位可执行文件的,后者是用来分析64位可执行文件的。一般先用IDA Pro 7.5 SP3 x64,它会提示你可执行文件是64位还是32位的,打开它,点击new,选择要分析的可执行文件,把本题的程序解压出来,选择pwn这个文件。{gird column="2" gap="15"}{gird-item} {/gird-item}{gird-item} {/gird-item}{/gird}然后软件会叫你选择文件的加载方式,这里什么都不用改,直接点OK就行,注意这里IDA识别出来了这个可执行文件的类型是ELF64 for x86-64,ELF是Linux下主要的可执行文件的文件格式,x86-64则代表该可执行文件是64位的:左边列出了该程序中所有的函数,包括程序内部定义的和链接外部的。我们选择main函数,先看看主函数:右边是main函数反汇编的结果,为了舒服我们一般都再反编译成C语言,摁下F5即可:int __cdecl main(int argc, const char **argv, const char **envp) { int v5; // [rsp+Ch] [rbp-4h] BYREF setbuf(stdout, 0LL); setbuf(stderr, 0LL); banner(); __isoc99_scanf("%d", &v5); while ( v5-- ) run(); return 0; }双击banner和run可以看到banner和run子函数的代码:可以看到banner这里给了一个提示,告诉你本题的程序其实是百练上一道上机题的解B:回文子串。int banner() { printf("This is a solution for this problem: %s\n", "http://bailian.openjudge.cn/xlylx2019/B/"); return puts("PWN it!"); }int run() { char s[104]; // [rsp+0h] [rbp-80h] BYREF int v2; // [rsp+68h] [rbp-18h] int k; // [rsp+6Ch] [rbp-14h] int j; // [rsp+70h] [rbp-10h] int i; // [rsp+74h] [rbp-Ch] int v6; // [rsp+78h] [rbp-8h] int v7; // [rsp+7Ch] [rbp-4h] __isoc99_scanf("%s", s); v2 = strlen(s); v6 = 0; for ( i = 0; i < v2; ++i ) { for ( j = i + 1; j <= v2; ++j ) { if ( (unsigned int)check(&s[i], (unsigned int)(j - i)) && v6 < j - i ) { v6 = j - i; v7 = i; } } } for ( k = v7; k < v7 + v6; ++k ) putchar(s[k]); return putchar(10); }至此,我们利用IDA工具成功获取了可执行程序的反编译代码,可以对程序逻辑进行分析了,因为编译过程中,会抹去变量名、函数名、部分结构信息等,所以反编译后的代码看起来会和我们正常写的不一样。细心的读者可能会发现题目给的另一个文件libc-2.31.so,这个文件的作用类似于Windows的dll文件,作为动态链接库向pwn提供库函数,接下来我们先讲解栈溢出漏洞的原理,这个文件将在之后的漏洞利用中登场。函数调用栈与栈溢出漏洞对于函数调用栈,比较细致的讲解可参考这篇文章: 手把手教你栈溢出从入门到放弃(上)。这里以比较通俗的文字给读者一个函数调用栈的基本映像。我们在调用函数的时候,函数内部可能又去调用其他函数,然后再回过头来继续执行,我们把外部函数称为父函数,内部函数称为子函数,因为要确保子函数执行完毕后,我们能继续执行父函数,那么我们需要保存父函数的地址、父函数的局部变量的值等父函数的状态信息,这时候栈这种结构就派上了用场,因为函数的多级调用是一个先入后出的行为,即越先被调用的函数越后执行完毕,这和栈的性质是对应的。当我们要执行子函数时,就把父函数的状态信息保存在栈中,然后再栈中分配新的空间给子函数,待执行完毕之后pop掉子函数的状态恢复父函数的状态继续执行就行了。因为接下来对于一些细节的讲解必须涉及到汇编,这里为不熟悉汇编的读者准备了一些讲解,可点开查看:{collapse}{collapse-item label="汇编基础知识"}BP、SP和IP寄存器寄存器主要是用来存储临时数据的,所谓临时就是值会经常发生改变。这里介绍一下和函数调用栈相关的特殊寄存器。RBP、EBP、BP其实都是指向一个长度为64位的寄存器,只不过RBP代表这个寄存器的全部64位,EBP代表低32位,BP代表低16位,如果是32位操作系统,就没有RBP,只有EBP和BP。同理SP和IP也是这种规则。RBP存储的可以理解成是当前执行函数状态的起始地址,RSP存储的是当前函数调用栈中最后一个元素的有效地址,也就是栈顶的位置。{message type="warning" content="注意因为函数调用栈从高地址往低地址增长的,所以其实栈顶的地址是最低的地址,也就是RSP中存储的地址<=RBP中存储的地址"/}RIP寄存器存储的是当前执行指令的地址,可以利用跳转指令来修改RIP的值,使其跳转到system或exec等函数执行一些可以入侵到目标主机的代码,比如说system("/bin/sh"),这也是Pwn题的最终目标。PUSH和POP指令PUSH指令就是将操作数压入栈中,具体就是先减小RSP的值,然后把操作数赋值到RSP指向的地址。例如PUSH EBP。POP指令就是将栈顶的元素弹出来,赋值给操作数。例如POP EBP。MOV指令通常写作MOV DST, SRC即将SRC的值赋值给DST,某些时候也会写成MOV SRC, DST。CALL、JMP和RET指令CALL指令先把RIP的值压入栈中,然后跳转到操作数指向的地址。JMP指令直接跳转到操作数指向的地址,即把操作数的值赋值给RIP。RET指令从栈顶中取出地址赋值给RIP。{/collapse-item}{/collapse}接下来我们来用通俗的语言解释一次子函数调用的过程:{mtitle title="子函数调用的过程"/}{timeline}{timeline-item color="#19be6b"} 父函数准备子函数的参数:在32位操作系统中,会用PUSH指令,从右到左,依次把子函数的实参压入栈中;在64位操作系统中,优先用寄存器传递参数,子函数的实参从左到右会被赋值给RDI、RSI、RDX、RCX、R8和R9寄存器,如果还有更多参数才会PUSH到栈上。{/timeline-item}{timeline-item color="#19be6b"} 执行CALL指令调用子函数:先把RIP的值压入栈(也就是父函数下一条指令的地址),然后将子函数第一条指令所在的地址赋值给RIP实现跳转。{/timeline-item}{timeline-item color="#409eff"} 保存父函数的EBP:PUSH EBP{/timeline-item}{timeline-item color="#409eff"} 当前栈顶作为子函数的EBP:MOV EBP, ESP{/timeline-item}{timeline-item color="#409eff"} 执行子函数的逻辑......直到执行完毕{/timeline-item}{timeline-item color="#409eff"} 保存子函数的返回值:用RAX寄存器保存子函数的返回值,用MOV指令把返回值赋值给RAX{/timeline-item}{timeline-item color="#409eff"} 恢复父函数的EBP:POP EBP{/timeline-item}{timeline-item color="#409eff"} 返回父函数:RET(从堆栈中取出之前保存的父函数返回地址赋值给RIP){/timeline-item}{timeline-item color="#19be6b"} 继续执行父函数的代码......{/timeline-item}{/timeline}函数调用栈用一张图表示为(图片引用自手把手教你栈溢出从入门到放弃(上)):{message type="info" content="1、Caller代表父函数,Callee代表子函数2、arg代表子函数的参数3、Local Variables为子函数的局部变量"/}所谓栈溢出,就是让局部变量的值覆盖掉Return Address,使得子函数返回的时候跳转到特定的地址执行一些危险代码。那么,怎么局部变量的值覆盖掉Return Address呢?因为C语言不检查数组的索引是否越界,因此这一点经常被利用来实现栈溢出攻击。在本题中,我们注意到run函数中有一个__isoc99_scanf函数(其实就是scanf函数)读入数据到局部变量s上:字符串读入的时候,是从低地址到高地址依次赋值的,因此只要输入的字符串够长,就可以覆盖掉Return Address:ROP与栈溢出漏洞的利用ROP中文名是面向返回的编程,顾名思义就是利用已有的动态链接库和可执行文件,提取出可以利用的指令片段(gadget),这些指令片段均以RET指令结尾,即用RET指令实现指令片段执行流的衔接(前面提到过RET会把栈顶的元素赋值给RIP),最后完成期待的恶意行为。我们最终的目的是让程序执行一个可以控制shell的代码片段(gadget),那么怎么知道这种代码片段所在的位置呢?这里可以利用一个one_gadget工具,下载方法为:sudo apt -y install ruby sudo gem install one_gadget用起来也很简单,pwn中是不可能有这种函数的,只能在libc-2.31.so中找:one_gadget libc-2.31.so然后工具会告诉你有哪些可以控制目标主机的代码片段,这些代码片段的位置,以及需要满足的条件:这里我们就利用0xe6c7e这个位置的gadget,注意限制条件是:对于r15,要么r15保存的这个地址指向0,要么r15本身是0。对于r12,要么r12保存的这个地址指向0,要么r12本身是0.为便于说明,下面我们称上面这个代码片段为gadget1。有了控制目标主机的gadget,怎么才能跳转到它并满足上述限制条件呢,可分为两步:因为目标主机可能开启了ASLR(即每次运行程序,栈的地址和动态链接库的地址随机变化),所以我们首先要设法得到gadget1在内存中的位置(上面那个0xe6c7e只是个相对地址),这里主要利用这样一个性质:.so文件中两个函数的相对地址(即两个地址的差)和加载到内存中的相对地址是一样的。其次我们需要一段gadget来控制r15和r12寄存器的值。对于第一步,我们需要调用.so文件中的puts函数,打印出某个函数在内存中的地址,并据此计算出相对地址,所以我们需要控制rdi寄存器的值(也就是控制puts函数的参数),在pwn程序中搜索寄存器的名称就能发现下面这一段代码:0x4013ba后面这一段代码可以控制rbx、rbp、r12、r13、r14、r15寄存器的值,0x4013a6则可以控制edi寄存器的值。攻击载荷的巧妙构造目前,我们需要的gadget都已经找齐,接下来就只需要巧妙的构造攻击载荷,让程序最终执行到gadget1。具体来讲,首先需要控制程序,打印出.so中某个函数的地址,然后我们可以计算出函数加载到内存前后的相对位置,然后可以据此计算出当前内存中的gadget1的位置,然后再让程序跳转到这个地址。Step1: 获得相对地址下面这张图展示的攻击载荷将会使程序打印出当前内存中printf函数的地址:程序会先跳转到0x4013ba,然后将rbx的值修改为1,rbp的值修改为2,以此类推,然后程序会跳转到0x4013a6,并修改edi的值,然后执行call指令,调用我们指定的puts函数,为了让程序不至于崩溃,我们最后控制它返回到了main函数。用该地址减去.so文件中printf函数的地址,得到的就是函数加载到内存前后的相对地址。Step2: 跳转到gadget1和Step1类似,先跳转到0x4013ba控制r12和r15寄存器的值,然后跳转到0xe6c7e即可。最后成功入侵系统的截图:{anote icon="fa-download" href="https://www.liuyh.com/usr/uploads/2022/02/493363414.txt" type="success" content="参考代码"/}最后pwn题是CTF比赛非常常见的题型,对于初学者来讲,因为解题涉及到太多需要实操的底层知识,上手难度会比较大,但实际上对于较强的选手来说,这类题型因为出题的套路不是很多,所以反而做起来比较容易。希望通过这篇文章能让读者对这类题型有个初步的认识。